
Qui utilise fréquemment Chatte Il le sait bien: les réponses qu’il nous donne ne sont pas toujours correctes. Il arrive souvent que le modèle, sur un ton sûr, donne information qui semblent plausible mais en réalité ils sont faux. Dans le monde de l’intelligence artificielle, ce phénomène est appelé hallucinationet concerne tous les modèles de langue (non seulement Chatgpt, mais aussi Claude, Gemini, Deepseek et autres).
Depuis un certain temps, la recherche universitaire a essayé de comprendre pourquoi cela se produit et comment réduire le problème. Début septembre 2025, OpenAI a publié une analyse dans lequel il essaie d’expliquer les principales causes des hallucinations et de proposer certaines solutions.
Selon l’étude, une partie du problème dépend de la façon dont les modèles sont évalués pendant la formation. Aujourd’hui, en fait, un modèle est « récompensé » s’il essaie de deviner une réponse, même lorsqu’il n’est pas certain qu’il est correct. Apprenez donc qu’il vaut mieux inventer quelque chose plutôt que d’admettre que vous ne savez pas. En modifiant cette approche, les hallucinations pourraient diminuer et les systèmes deviennent plus fiables.
Voyons plus en détail ce que sont les hallucinations, ce que Openai a découvert et quelles conséquences il apporte.
Que sont les hallucinations de chatpt
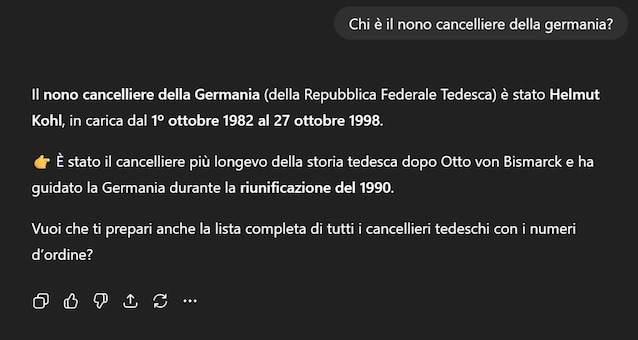
Dans le contexte de l’intelligence artificielle, Une hallucination est une réponse qui semble correcte Mais en réalité, il est inventé ou sans fondation. Par exemple, nous avons demandé à Chatgpt: « Qui est le neuvième chancelier allemand? ». Dans trois tentatives différentes, à partir de différents comptes et à différents moments de la journée, le modèle a répondu: Willy Brandt, Helmut Kohl et Olaf Scholz. Seul ce dernier est correct: les deux autres réponses étaient des hallucinations.
Les hallucinations naissent parce que les modèles de langue ont été conçus pour générer du texte cohérent et naturel, pour ne pas remplacer un moteur de recherche ou fournir des données parfaitement précises.
Parce que les hallucinations ont lieu et comment essayer de les atténuer: l’étude
Dans son article « Pourquoi les modèles de langue halulucinés » (« parce que les modèles de langue ont des hallucinations »), Openai explique que le problème dérive de façon dont les modèles sont formés Et évalué: Pour maintenant, un modèle a été considéré comme « mieux » s’il donnait des réponses plus correctes. Par conséquent, les modèles de langue (LLM) Ils sont formés pour essayer de donner une réponse, même inventé, au lieu d’admettre de ne pas savoir. Les auteurs comparent ce mécanisme à celui des étudiants non préparés devant une vérification transversale: s’ils ne connaissent pas la réponse, ils préfèrent deviner au lieu de laisser la boîte vide, car de cette manière ils ont encore une chance de gagner des points.
Ensuite, il y a deux autres causes qui conduisent le LLM à faire des erreurs:
- La qualité des données: Si dans les textes utilisés pour la formation, il y a des erreurs, le modèle les répétera dans les réponses. C’est le principe de « ordures dans, ordures »: si je saisis les ordures (données incorrectes), j’obtiendrai des ordures (mauvaises réponses).
- Les limites de la connaissance: Même si les données ne contenaient aucune erreur, elles ne pouvaient cependant pas couvrir toutes les connaissances des connaissances et des réponses humaines. Certaines questions ne répondront pas aux données, et le modèle, ayant appris qu ‘ »il vaut mieux dire quelque chose que d’admettre l’ignorance », finira par inventer.
Ces idées ne sont pas entièrement nouvelles dans le domaine de la recherche sur les hallucinations, la nouveauté introduite par Openai est l’idée de changer la façon dont nous évaluons les réponses: pénaliser beaucoup plus le erreurs Et récompenser l’honnêteté du « Je ne sais pas ». De cette façon, nous visons à créer des modèles plus « humbles », atténuant ainsi le problème des hallucinations.
Qu’est-ce qui est fait pour résoudre le problème
Même avant cette recherche, les entreprises avaient connu certaines solutions pour réduire les hallucinations. L’un des plus communs est leUtilisation de sources externes en temps réel, comme le Recherches sur le Web. Cette technique réduit les hallucinations, même si elle ne les élimine pas complètement.
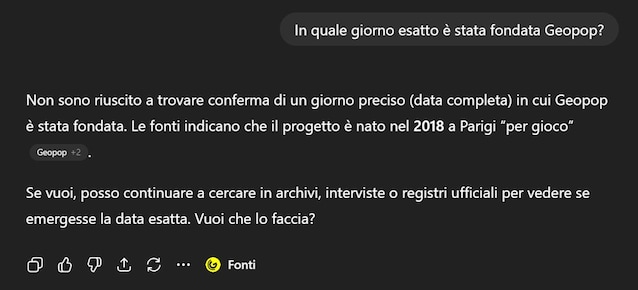
Avec l’arrivée de GPT-5, les progrès sont devenus plus évidents. Aujourd’hui, face à des questions trop spécifiques, telles que « le jour exact de Geopop a-t-il été fondé? », Le modèle admet qu’il ne connaît pas la réponse, qui est impensable avec les versions précédentes.
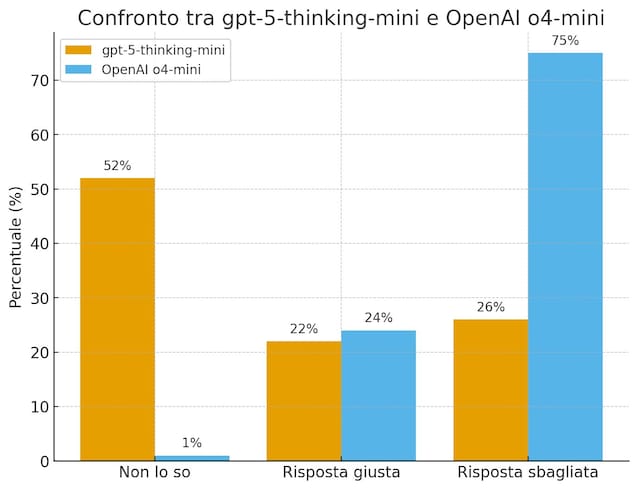
Selon les données d’OpenAI, lorsqu’ils ont testé le nouveau modèle GPT-5-Thinking-min (la version « plus petite » et moins puissante de GPT-5) sur un ensemble de données créé exprès pour mesurer la possibilité de faire la vérification des faits, admis à Je ne sais pas Dans 52% des cas (contre 1% de la version précédente) et engagé Moins d’erreurs (26% contre 75%). Le pourcentage de réponses exactes était légèrement plus faible (22% par rapport à 24%), mais la qualité globale s’est améliorée: mieux un modèle qui admet ses limites, plutôt que celui qui a mal tort.
Un autre front de recherche sur lequel Openai travaille concerne le langue avec lequel l’AI communique l’incertitude. Dans notre premier exemple, cela aurait été très différent si Chatgpt répondit: « Peut-être que le neuvième chancelier pourrait être Kohl » au lieu de nous donner la mauvaise réponse avec une grande sécurité. Une telle réponse aurait rendu plus évident que ce n’était pas un certain fait.
Cependant, un très gros problème reste ouvert: plus le réponses Je suis long Et structuréplus augmenter Le risque De hallucinations. Ce problème est beaucoup plus difficile à résoudre et la solution proposée par OpenAI ne suffit pas. Cette étude, cependant, est un signe positif dans la bonne direction: il est clair qu’OpenII travaille pour obtenir une IA plus fiable. Et en attendant, nous, les utilisateurs, pouvons continuer à l’utiliser avec un esprit critique, en vérifiant toujours les réponses que nous obtenons.