
L’intelligence artificielle fait de grands progrès dans le secteur de la génération de vidéos, E Omnihuman-1la dernière création de Bytedance (L’entreprise qui développe Tiktok), c’est une manifestation claire. Ce nouveau modèle d’IA est capable de produire unfake extrêmement réalistesurmonter bon nombre des limitations techniques qui, dans le passé, ont rendu ces contenus reconnaissables. Contrairement à d’autres systèmes, qui trahissent souvent leur nature artificielle avec des détails imparfaits, Omnihuman-1 parvient à générer des vidéos dans lesquelles le visage et les mouvements sont incroyablement naturels, ce qui rend plus difficile la distinction entre réel et synthétique.
Le modèle n’a besoin que d’une image de référence unique et d’une piste audio pour générer un film de la longueur souhaitée, adaptant également le format et la partie du corps visible. Était formé sur environ 19 000 heures de contenu vidéobien que Bytedance n’ait pas spécifié les sources à partir desquelles le matériel de formation vient. En plus de créer de nouvelles vidéos, Omnihuman-1 peut également modifier les prises de vue existantes, modifiant même les mouvements des personnes présentes dans la vidéo. Il faut dire que la qualité de la sortie dépend de la résolution de l’image de départ et que le modèle peut avoir des difficultés avec des poses particulièrement complexes. Il n’est actuellement pas accessible au public.
Comment fonctionne Omnihuman-1
Omnihuman-1 utilise une combinaison de Techniques d’intelligence artificielle avancées pour générer des vidéos dans lequel le sujet semble incroyablement naturel. Contrairement à Deepfakes « traditionnels », qui nécessitent de nombreuses images de référence pour créer une vidéo crédible, ce système est capable de générer une vidéo complète à partir d’une seule image et d’un fichier audio. Pour générer le contenu, le modèle utilise un Réseau de neurones avancé qui a été formé sur un ensemble de données impressionnant: Ben 18 700 heures de contenu.
L’un des aspects les plus innovants d’Omnihuman-1 est la possibilité de Ajustez divers paramètrescomme le « Proportion corporelle »qui définit la quantité de corps humain doit être visible dans la vidéo générée et la longueur du clip final. Cette flexibilité permet au système de s’adapter à une large gamme de scénarios, augmentant la polyvalence dans la production vidéo.
L’un des éléments clés qui rend omnihuman-1 particulièrement puissant est leintégration de différents types d’entréesy compris le texte, l’audio et la pose. Lorsqu’une entrée est donnée, le système est capable de générer une vidéo qui ne correspond pas seulement au mouvement du corps du sujet, mais aussi à la synchronisation labiale et à l’expressivité faciale. L’intelligence artificielle d’Omnihuman-1 est en fait capable de « lire » le mouvement naturel du corps humain, grâce à un processus de formation basé sur un énorme volume de données, qui comprend les différentes façons d’expression et d’interactions vocales.
Comme schématisé par l’image que vous trouvez plus tard, le Système omnihuman Il est divisé en deux composantes principales:
- Le Modèle omnihumanqui utilise le modèle DIT de Deep Learning, permet le conditionnement simultané de différentes manières telles que le texte, l’image, l’audio et les poses du corps humain.
- La stratégie de Formation « omnicprante »qui adopte un processus d’apprentissage plus en phase, dans lequel la progression dépend de l’intensité des conditions relatives au mouvement. L’approche de formation avec des conditions mixtes permet au modèle omnihuman d’exploiter la capacité de gérer un grand volume de données variables.
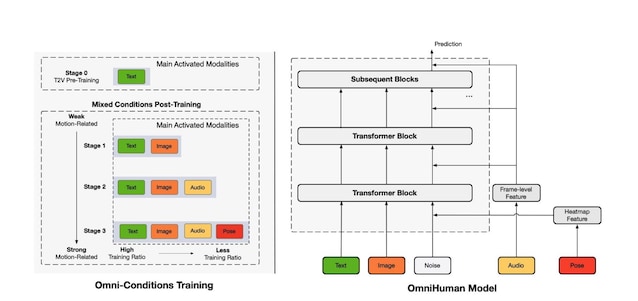
Le processus de formation Omnihuman-1 a été conçu pour optimiser les compétences du modèle pour générer des vidéos. Initialement, le système apprend à générer des vidéos en fonction des entrées de faible complexité, telles que du texte et des images, puis d’intégrer des signaux audio et pose. Ce Approche « multi-conducteur » Permet au système de perfectionner ses compétences et d’améliorer la qualité finale des sorties.
Malgré l’efficacité du système, les développeurs de bydance admettent qu’il y en a encore limitescomme le Difficulté à élaborer des images de faible qualité ou difficultés à générer des sujets avec des poses articuléesmais il est clair que la technologie est en évolution constante et à l’avenir, le modèle devrait améliorer ces fronts. Dans les vidéos suivantes, en attendant, vous pouvez apprécier certaines vidéos générées avec Omnihuman-1. Jugez-vous à quel point ils sont plus ou moins réalistes!
Préoccupations sur les fesses profondes ultra-réalistes telles que Omnihuman-1
Si, d’une part, ce type de technologie ouvre de nouvelles possibilités de divertissement et de création de contenu numérique, d’autre part Des défis importants sur le front de la sécurité et de l’éthique. Ces dernières années, Deepfakes a été utilisé dans des campagnes de désinformation politique dans différents pays du monde. À Taïwan, par exemple, un audio généré par l’IA était répandu dans lequel un politicien semblait soutenir un candidat pro-Cinois, tandis qu’une fausse vidéo de la démission présumée du président a circulé en Moldavie. Même dans le secteur financier, les Deepfakes sont utilisés pour des escroqueries sophistiquées, avec des entreprises qui ont subi des pertes millionnaires en raison d’imitations des gestionnaires et des célébrités.
Sans surprise, l’impact économique attribuable à la prolifération du contenu synthétique est significatif. Selon une relation de Deloitteen 2023 le Les pertes liées à la fraude avec Deepfakes ont dépassé 12 milliards de dollars Et ils pourraient atteindre 40 milliards d’ici 2027 uniquement aux États-Unis! Bien que certains réseaux sociaux et plateformes de recherche aient commencé à mettre en œuvre des outils pour identifier et limiter la propagation du contenu falsifié par l’IA, le volume de ces matériaux continue de croître rapidement. Et étant donné la naissance des instruments du calibre d’Omnihuman-1, ce phénomène est destiné à se développer.